推广软件赚佣金
扫描下方二维码
400-8765-888
工作时间:9:00-20:30(工作日)
发布时间:2015-08-26 11: 18: 16
图片文字识别软件ABBYY FineReader是现在办公室的必备软件,它可以识别JPG、GIF、PNG、BMP、TIF和PDF源文件、PDF扫描件,也就是说我们在日常工作中能够遇到的不能编辑的文字都可以通过ABBYY FineReader图片文字识别软件来识别,识别得到的文字可以自由的进行编辑。有很多人有这样的疑问,图片文字识别软件的技术原理是什么呢?
1、图文输入:是指通过输入设备将文档输入到计算机中,也就是实现原稿的数字化。现在用得比较普遍的设备是扫描仪。文档图像的扫描质量是OCR软件正确识别的前提条件。恰当地选择扫描分辨率及相关参数,是保证文字清楚、特征不丢失的关键。此外,文档尽可能地放置端正,以保证预处理检测的倾斜角小,在进行倾斜校正后,文字图像的变形就小。这些简单的操作,会使系统的识别正确率有所提高。反之,由于扫描设置不当,文字的断笔过多可能会分检出半个文字的图像。文字断笔和笔画粘连会造成有些特征丢失,在将其特征与特征库比较时,会使其特征距离加大,识别错误率上升。
2、预处理:扫描一幅简单的印刷文档的图像,将每一个文字图像分检出来交给识别模块识别,这一过程称为图像预处理。预处理是指在进行文字识别之前的一些准备工作,包括图像净化处理,去掉原始图像中的显见噪声(干扰)。主要任务是测量文档放置的倾斜角,对文档进行版面分析,对选出的文字域进行排版确认,对横、竖排版的文字行进行切分,每一行的文字图像的分离,标点符号的判别等。这一阶段的工作非常重要,处理的效果直接影响到文字识别的准确率。 版面分析是对文本图像的总体分析,是将文档中的所有文字块分检出来,区分出文本段落及排版顺序,以及图像、表格的区域。将各文字块的域界(域在图像中的始点、终点坐标),域内的属性(横、竖排版方式)以及各文字块的连接关系作为一种数据结构,提供给识别模块自动识别。对于文本区域直接进行识别处理,对于表格区域进行专用的表格分析及识别处理,对于图像区域进行压缩或简单存储。行字切分是将大幅的图像先切割为行,再从图像行中分离出单个字符的过程。
3、单字识别:单字识别是体现OCR文字识别的核心技术。从扫描文本中分检出的文字图像,由计算机将其图形、图像转变成文字的标准代码,是让计算机“认字”的关键,也就是所谓的识别技术。就像人脑认识文字是因为在人脑中已经保存了文字的各种特征,如文字的结构、文字的笔画等。要想让计算机来识别文字,也需要先将文字的特征等信息储存到计算机里,但要储存什么样的信息及怎样来获取这些信息是一个很复杂的过程,而且要达到非常高的识别率才能符合要求。通常采用的做法是根据文字的笔画、特征点、投影信息、点的区域分布等进行分析。
上述这三个是图片文字识别软件ABBYY Finereader识别过程中的技术原理,一些技术不成熟的软件每一个步骤都需要用户手动进项操作,所以没有一定的专业知识完成不了整个过程。而ABBYY FineReader图片文字识别软件因为技术成熟、智能化程度高,这些都是程序都是软件自动完成,一键完成识别工作。
想要了解关于ABBYY FineReader 的更多内容可点击进入ABBYY中文教程中心,查找您想要了解的内容。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >

怎么将PPT转换成Word PPT转换成Word排版乱了
工作时常常会有将PPT转换Word文档的需求,有时会遇到一些棘手的问题。例如:怎么将ppt转换成Word ,ppt转换成Word排版乱了。下面就跟着小编一起来学习一下吧。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >
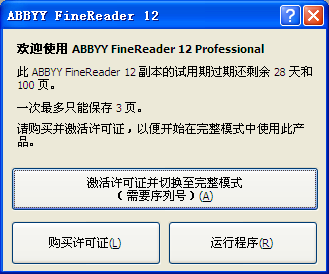
ABBYY FineReader 12激活教程
安装完 ABBYY FineReader 12 之后,需要激活程序才能在完整模式下运行。在受限模式下,将根据您的版本和所在地区禁用一些功能。...
阅读全文 >






 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 
