发布时间:2015-10-14 13: 40: 53
这是一篇来自新浪网友的测评,“我是看到abbyy官方微博的活动才写的这篇评测,ABBYY FineReader这款老牌OCR软件时隔几年终于再次更新了,经过几天试用版的测试,我写下这篇使用心得。同时也夹杂着对ABBYY FineReader12的更新的地方的一些理解。”本文为上半部分。
以下ABBYY FineReader12简称12版,ABBYY FineReader11简称11版。
高质量图片比较
首先我们以一张质量比较高的杂志图片作为识别素材,图片出自杂志《桌游Club》2013年6月号,选择这个素材的原因有几点:
一、素材的质量非常好,没有任何噪声和阴影,能把这些不确定因素降到很低,非常适合用来进行OCR识别。
二、素材的字体和版式均有一定的复杂程度,素材内还有一个表格和一张图片,非常适合检验字体和版式的还原效果。
三、素材的语种中文为主,含有少量英文,可以检测中英文混排的效果。
四、素材的内文原作者为本文本人,本人有素材内文本的原始文档,可以最准确地检测OCR结果的识别率。

图1
以下是ABBYY 11的识别效果图:
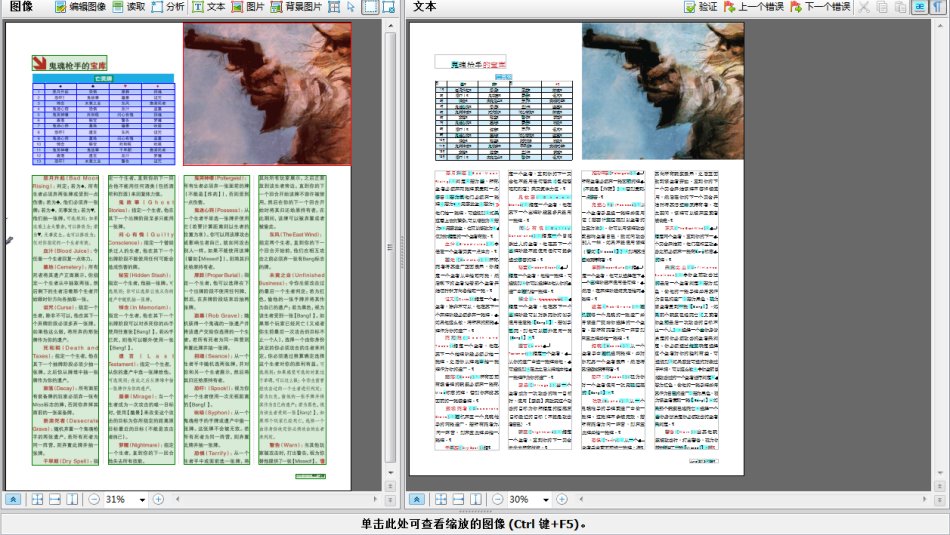
图2
以下是ABBYY 12的识别效果图:
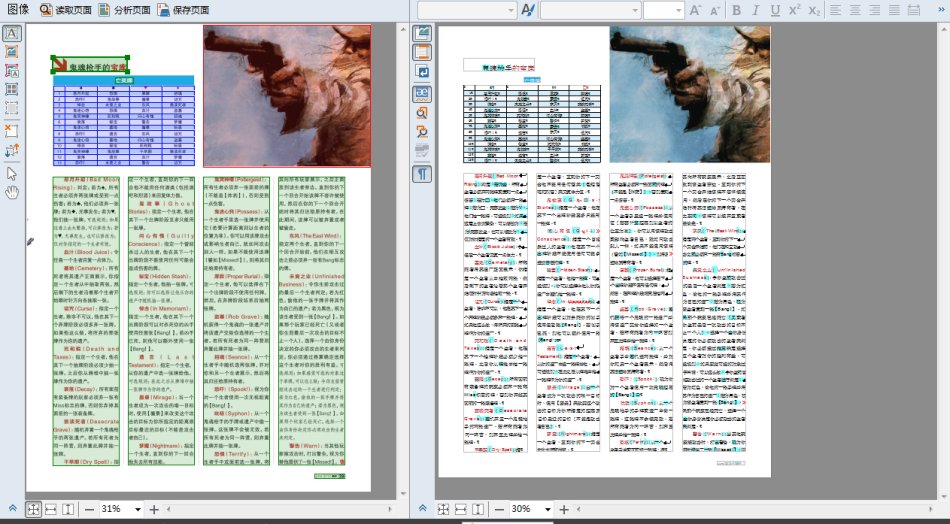
图3
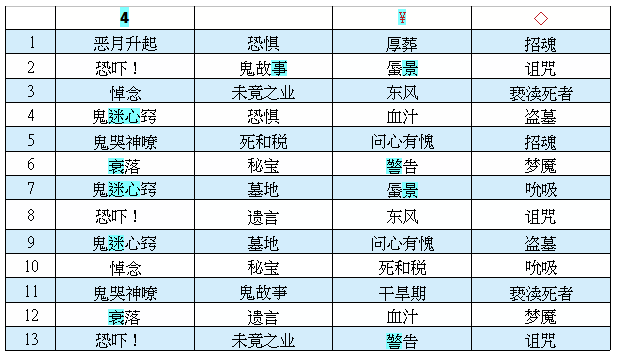
图4 12版表格识别效果

图5 12版内文识别效果
将输出的文本经过文字处理软件与我的原始文稿进行对比,可以发现:
一、11版和12版均做到了文本的版式的完整还原。
二、除了若干括号和冒号的差异之外,11版和12版只有4处差异,和我的原始文稿也只有4处差异,差异分别是:
|
11版 |
12版 |
原始文稿 |
|
Ghost |
Gh〇st |
Ghost |
|
Guilty |
Gui11y |
Guilty |
|
鬼迷心?§ |
鬼迷心窍 |
鬼迷心窍 |
|
巳经 |
已经 |
已经 |
可以看出,在图片质量非常好的情况下,11版和12版已经做到了很高的识别率,为2/1730=99.88%。12版的中文的识别率更是做到了可喜的100%。同时,虽然牺牲了一些英文字符的识别率,但是在中英文混排的情况下12版对中文字符的识别比11版做得更好,同时一定程度地解决了11版固有的几个问题:
1、不确定字符识别成特殊符号。笔者使用11版时,识别中文时经常出现类似于“£〃•€■|”诸如此类的特殊符号,譬如在本次测试中的“§”。而此次测评在12版中没有此类问题。
2、常用字识别成形状接近的生僻字。笔者使用11版时,识别中文时经常出现将常用字识别成形状接近的生僻字的情况,譬如 “查”识别成“査”,“开”识别成“幵”和此次测试中的“已”识别成“巳”。而此次测评在12版中没有此类问题。
3、12版在中英文混排的情况下牺牲了一定的英文的识别率。由于目前文档处理软件的英文拼写检查技术已经相当成熟,这方面的问题完全可以同过英文拼写检查这一手段解决。而中文的拼写检查技术还很不完善,故提高中文的识别率更加重要。
4、美中不足的是,11版和12版均未能做到对扑克牌花色这一特殊字符的识别,只有12版识别了“◇”。
5、不知道是否是试用版的缘故,12版虽然将文字的颜色识别出来了,但是在保存为word后这些颜色都消失了。
更多关于ABBYY FineReader的内容, 请点击进入ABBYY中文教程中心,查看您需要的信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >
ABBYY FineReader 12激活教程
安装完 ABBYY FineReader 12 之后,需要激活程序才能在完整模式下运行。在受限模式下,将根据您的版本和所在地区禁用一些功能。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 