发布时间:2017-04-17 09: 39: 17
ABBYY FineReader 14其中一个亮点莫过于PDF Editor(PDF编辑器)了,这个功能允许用户搜索并复制没有文本层的PDF文档里的文本和照片,比如扫描的文档和从图像文件创建的文档,而这都归功于在文档背景中运行的OCR过程。
ABBYY FineReader 14背景识别是默认启用的,并且在打开PDF文档的时候自动开始工作。
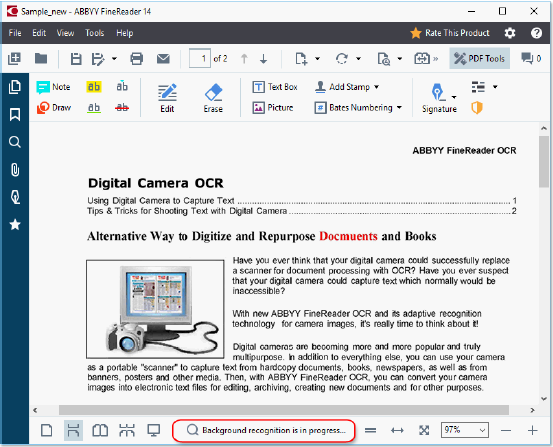
背景识别过程不会改变PDF文件的内容,相反,它会添加一个临时的文本层,这个文本层在你在其他应用程序中打开文档时不可用。
如果你希望文档在其他应用程序中可搜索,则需要保存背景识别过程创建的文本层,点击File > Recognize Document > Recognize Document(文件 > 识别文档 > 识别文档)。
ABBYY FineReader 14的背景识别是一个过程,它会给文档添加一个临时的文本层,让你可以标记、复制和搜索其文本。你也可以通过添加永久的文本层到PDF文档,让这些功能对其他用户可用。带有文本层的文档和它们的原件几乎没有区别,你还可以替换可搜索的PDF文档中现有的文本层。
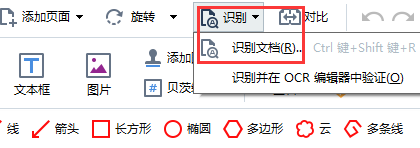
1、在主工具栏上,点击‘识别’旁边的箭头,从下拉列表中选择Recognize Document(识别文档)。或者,点击File > Recognize Document > Recognize Document(文件 > 识别文档 > 识别文档) 或按Ctrl+Shift+R快捷键。
2、在打开的对话框中,指定合适的OCR语言。
3、启用图像处理提高OCR质量,图像处理可能会改变你的文档外观。
•纠正页面方向—程序会检测文本方向并在必要的时候纠正文档方向。
•歪斜校正图像并纠正图像分辨率—程序会检测并纠正所有的歪斜,选择正确的图像分辨率,并做一些其他修改来提高图像质量。
4、点击Recognize(识别)按钮。
5、输出的文档将包含可搜索的文本层。
你也可以在从文件添加页面到PDF文档或扫描纸质文档的时候添加文本层,在‘图像处理设置’对话框(点击‘添加页面’ > 图像处理设置来打开该对话框)中选择‘识别图像上的文字’选项,并指定文档的语言。
如果你想检查识别的文本,训练程序识别非标准字体和字符,或者使用ABBYY FineReader 14的其他一些高级功能,可以点击‘识别’按钮旁边的箭头,然后点击‘识别并在OCR编辑器中验证’。
若要禁用背景识别,需清除‘选项’对话框中的‘在PDF编辑器中启用背景识别’选项。
有关ABBYY FineReader 14的更多内容,请点击访问ABBYY教程了解更多信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

ABBYY是免费的吗 ABBYY正版软件多少钱
在我们日常工作中,你是不是也经常遇到一些文字识别方面的问题,如果我们按照传统的方式,逐字逐句地手动输入将图文转化为文本,会浪费很多时间。所以,今天小编给大家推荐一款OCR文字识别软件,它就是ABBYY FineReader PDF 15。它可以自动扫描并提取图片上的文字内容,方便我们复制粘贴以及编辑。下面就讲讲大家关心的问题ABBYY是免费的吗,ABBYY正版软件多少钱。...
阅读全文 >
PDF转成图片的方法 PDF转图片不清晰怎么办
PDF文档和图片都是常用的文件格式,在工作中我们需要根据不同的需求来灵活地对文件的格式进行更改,这就需要我们掌握PDF转成图片的方法。PDF转图片不清晰怎么办?下文中会为大家进行详细地解答。...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 