发布时间:2015-09-30 11: 05: 34
ABBYY FineReader是一款图文识别(OCR)软件,在识别文本时使用文档语言相关的数据,对于包含很多非常用元素(如代码编号)的文本,程序可能无法识别某些字符,因为文档语言可能没有包含此类字符,要识别此类文档,可创建自定义语言,其中包括了所有需要的字符,也可分配多种语言给语言组,然后使用这些组进行识别,本文将为大家讲解如何在ABBYY FineReader中创建用户语言。
步骤一:在工具菜单中,点击语言编辑器;
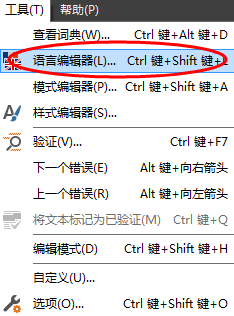
步骤二:在语言编辑器对话框中,点击新建;
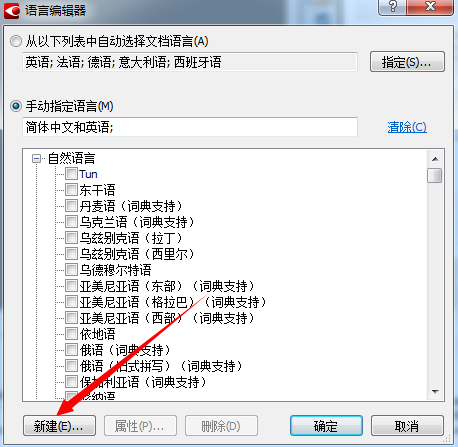
步骤三:在打开的对话框中,选择根据现有语言创建新语言选项,然后选择新语言所依据的语言并点击确定;
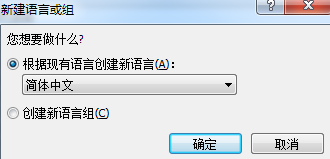
步骤四:将打开语言属性对话框,在此对话框中:
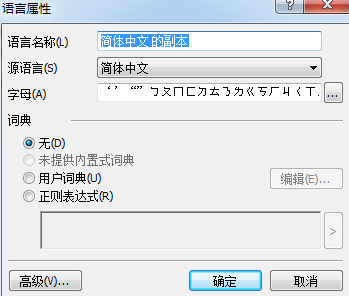
1、输入新语言的名称。
2、之前选择的基础语言将显示在源语言下拉列表中,可更改源语言。
3、字母包含了基础语言的字母。点击 按钮以编辑字母。
按钮以编辑字母。
4、程序识别文本和检查结果时,将会用到几个与词典相关的选项:
a、无 语言将不会有词典;
b、内置式词典 将使用程序的内置词典;
c、用户词典 点击编辑(E)...按钮以指定词典项目,或导入现有自定义词典或带有Windows–1252编码的文本文件(项目之间必须以空格或以其他非字母表中的字符隔开);
注:检查所识别文本的拼写时,不会将用户词典中的单词标记为错误,它们可能全部使用小写字母或大写字母,或者可能以大写字母开头。
d、正则表达式 可使用正则表达式创建自定义语言词典。
5、语言可具有其他几种属性。点击高级(V)...按钮可以更改这些属性。
步骤五:选择文档语言时可选择新创建的语言。
默认情况下,用户组会保存在FineReader文档文件夹中,可以将所有用户语言和用户模式另存为单个文件。为此,在工具菜单中,点击选项,打开选项对话框,点击读取选项卡,然后点击保存到文件(S)...按钮。
更多关于ABBYY FineReader的相关信息,可点击进入ABBYY中文服务中心,查看您需要的信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:
PDF转成图片的方法 PDF转图片不清晰怎么办
PDF文档和图片都是常用的文件格式,在工作中我们需要根据不同的需求来灵活地对文件的格式进行更改,这就需要我们掌握PDF转成图片的方法。PDF转图片不清晰怎么办?下文中会为大家进行详细地解答。...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >
pdf扫描的文件是歪的怎么办 pdf扫描件歪了如何调整
经常和文件扫描打交道的人都知道,如果文件没有摆正,扫描出来的pdf容易变歪。如果pdf扫描的文件是歪的怎么办呢?pdf扫描件歪了如何调整呢?以下会为大家提供解决方法。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 