发布时间:2017-02-08 17: 25: 14
准确地将扫描的纸质文档、图像和PDF文件转换为Word、Excel、可搜索的PDF及其他格式,受益于ABBYY FineReader 14强大的OCR技术,数字处理过程变得前所未有的快速和简单。相信不少人都已经体验过FineReader 12的转换技术,现在是时候感受新版本FineReader 14的转换功能了。
轻松将扫描纸质文档、PDF文件和图像转换为可编辑的Word、Excel和其他文件格式,无需重新输入,为更重要的任务节省大量时间,甚至可以同样轻松地同时处理批次个人文档。

优越的OCR准确性高达99.8%,ABBYY的文档布局和结构重建(包括页眉、页脚、页面编号等)智能技术以及精确的表格结构保留的结合,确保几乎无需任何手动纠正。
从任何扫描文件获取高质量的数字副本,FineReader会自动应用优质图像预处理算法,提供优秀的转换结果。你可以直接使用ABBYY FineReader扫描文档,任何类型的任务都可以使用多个扫描设置。
轻松将扫描的纸质文档转换为可搜索的PDF文件,或者在转换过程中,将它们与Word、Excel或其他很多格式的文件相结合,ABBYY FineReader还支持PDF/A格式,一种长期归档的标准格式。

通过压缩(高达20倍)减少PDF文档的大小,提高扫描文件的视觉质量,获得适合数字归档的可搜索的PDF文档。
OCR编辑器提供了高级文档转换所需的所有工具—给予你完全控制权,让你获得结果,即便是非常复杂的文档。设置和调整任何设置都有可能提高OCR和布局保留质量—比如,使用单元分隔符来保留复杂表格的结构。
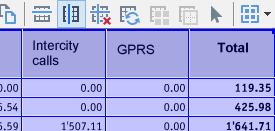
更快速地检查结果并纠正拼写错误:在FineReader中保存转换的文本之前执行这项操作,只需通过突出显示的符号确保100%的文档准确度,甚至还可以校对表格里的文本和数据。

如果你的文档经常包含特定领域的专业术语—或者使用罕见或装饰性的字体—那么就可以训练FineReader来正确地识别它们,获得更加准确的结果。
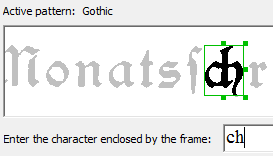
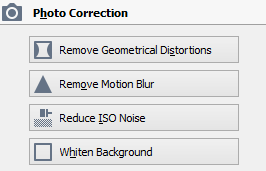
无论是你自己拍摄文档,还是接收文档图像来处理,ABBYY FineReader都能起到作用,它应用强大的图像预处理工具纠正图像失真,清理照片图像—产生的结果和扫描文件差不多,文本识别结果出乎意料。
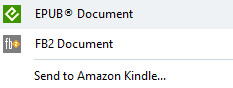
将扫描的书本和文章转换为电子书格式:EPUB、FB2,或者将它们发送到Amazon Kindle账户,在上下班路上阅读。
更多有关ABBYY FineReader的教程内容,请点击访问ABBYY教程了解更多。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

ABBYY怎么提高识别率 ABBYY怎么增加准确度
很多小伙伴反馈,在使用ABBYY FineReader软件进行文字识别的时候发现识别率比较低,想提高文字识别的准确度,但却不知道该怎么操作,为了方便大家能更好的使用ABBYY FineReader软件,下面我将来带大家了解一下ABBYY怎么提高识别率, ABBYY怎么增加准确度的相关内容。...
阅读全文 >

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 