发布时间:2021-04-08 11: 36: 37
尽管ABBYY FineReader PDF 15是一个识别度极高的OCR文字识别工具,但它在识别图片、PDF文件的时候还是会存在一定的遗漏和错误。其中,在识别表格的时候,有某些表格并不能完全识别出来。对于这种情况,很多小伙伴把识别的文件转换为Word文件后,再在Word软件中修改,这使工作量变得巨大。
实际上,在ABBYY的OCR编辑器中,通过调整对表格区域的识别,可以使表格的识别度达致百分百。下面小编通过一个实际的案例,讲述如何调整不能完全识别的表格。
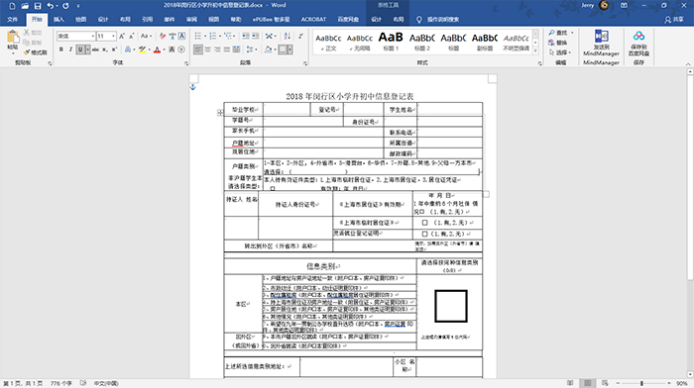
首先,使用ABBYY Finder PDF 15软件打开一个通过扫描纸质表格生成的PDF文件。由于纸质表格的清晰度并不高,使到扫描形成的PDF文件的效果也不是很好,这会令ABBYY的OCR编辑器识别发生错误,这在实际使用中普遍发生的问题。
点击“识别”按钮,选择“识别并在OCR编辑器中验证”。
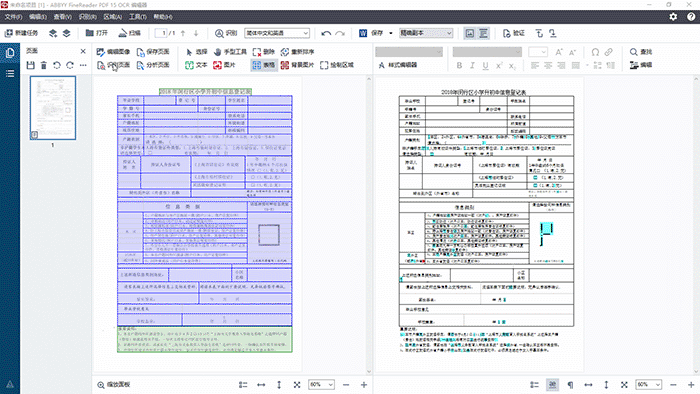
待识别结束后,在OCR编辑器界面中,检查右侧副本文件,发现表格并没有完全识别出来。例如:“登记号”左侧少了一条竖线;“非户籍学生……”缺失了左右两条竖线以及下面“签名”部分的表格都没有识别出来。此时注意,“保存格式”一定要选择“精确到副本”。

在左侧源文件上,删除处于表格内的文本框,在工具栏上点击“制表格区域”,通过调整、添加表格区域,重新对表格设置新的绘制表格区域。在设置的过程中,注意竖线对齐和横线重叠,避免识别后的表格边框出现不对齐以及粗细不一致的问题。

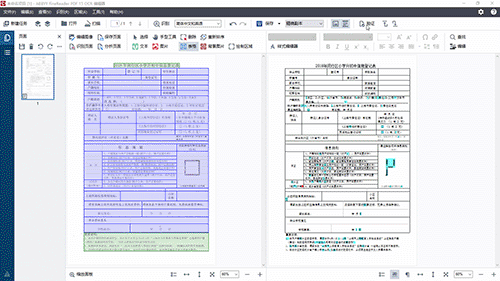
在源文件上重新绘制表格区域后,点击“识别页面”,对源文件进行重新识别。识别结束后,再次检查表格,发现副本的表格与原表格一致。
然后点击“验证”按钮,对识别错误的内容进行修改。错误修正后,源文件整个识别过程就完成了。
最后,把识别的文件保存为Word文档,实现了把扫描得到的表格转变为Word格式的电子文件。
总结
由于原纸质文件的清晰度以及扫描精度,都会导致形成的PDF文件里的内容模糊,从而令ABBYY FineReader PDF 15软件的OCR文字识别软件不能完全识别出表格的线条,使到表格产生缺失。但通过重新绘制表格区域后,再次识别基本就能获得完整的表格。
作者:东佛
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

OCR文字识别软件推荐 OCR文字识别怎么使用
在日常工作中,我们经常会遇到需要对PDF中的文字内容进行编辑或者需要把文件进行格式进行转换的情况,尽管网上有很多在线的OCR文字识别工具,但往往对文件的大小有限制,使用起来有很多局限性,接下来本篇内容就来为大家介绍一下OCR文字识别软件推荐,OCR文字识别怎么使用的相关内容。...
阅读全文 >
PDF转成图片的方法 PDF转图片不清晰怎么办
PDF文档和图片都是常用的文件格式,在工作中我们需要根据不同的需求来灵活地对文件的格式进行更改,这就需要我们掌握PDF转成图片的方法。PDF转图片不清晰怎么办?下文中会为大家进行详细地解答。...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >
pdf扫描的文件是歪的怎么办 pdf扫描件歪了如何调整
经常和文件扫描打交道的人都知道,如果文件没有摆正,扫描出来的pdf容易变歪。如果pdf扫描的文件是歪的怎么办呢?pdf扫描件歪了如何调整呢?以下会为大家提供解决方法。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 