发布时间:2021-05-19 09: 44: 25
ABBYY FineReader PDF 15配备了智能的OCR文本识别功能,不仅能识别PDF文档,而且还能识别纯图像文件,很适合用于纸质文件的数字化处理。
本文将会针对ABBYY FineReader PDF 15的图像文本识别功能,介绍一些图像识别的小技巧,提高软件的文本识别效率。
一、图像文件的预处理
图像文件的预处理,是ABBYY FineReader PDF 15提供的一项相当实用的功能,该功能可帮助我们预先处理一些拍摄失误,如页面方向错误、图像倾斜等。
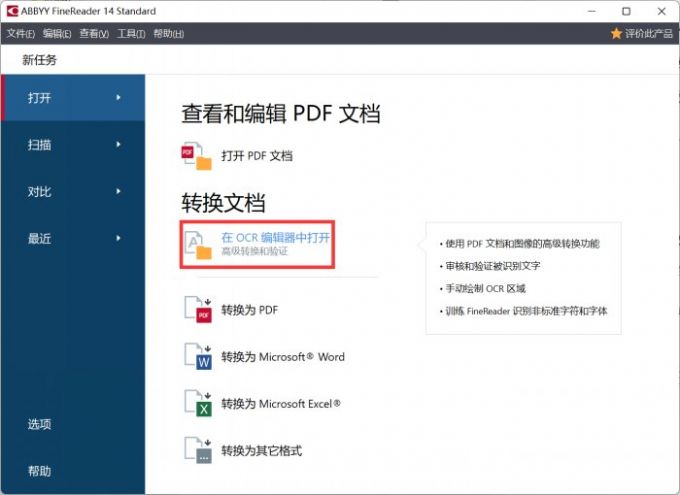
如图1所示,单击“在OCR编辑器中打开”功能,该功能可用于图像的文本识别。
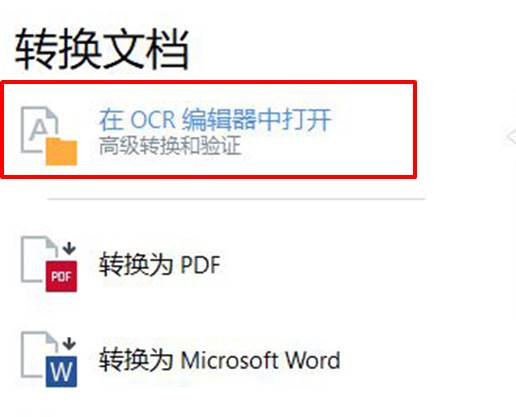
接着,如图2所示,在打开文件窗口的右下角出现的“添加页面时自动处理页面图像”的功能,勾选该选项即可在打开图像后,自动执行图像预处理操作。
那么,该功能包含了哪些预处理选项呢?我们可以单击“选项”按钮进一步了解。
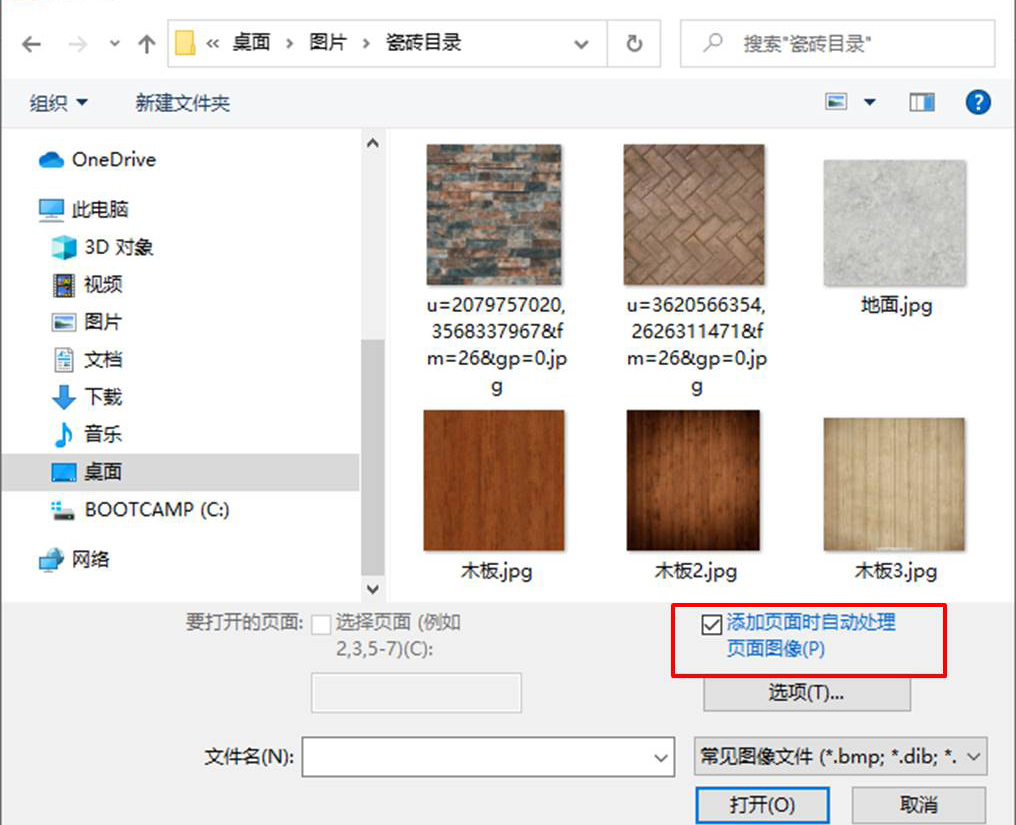
如图3所示,在“图像预处理设置”中,可以看到,ABBYY FineReader PDF 15默认开启了“拆分对开页”、“纠正页面方向”、“对图像进行歪斜校正”等图像处理功能。

以图4所示的图像为例,该图像包含了两个页面,并且存在页面方向错误。

完成了图像预处理后,如图5所示,可以看到,图像已经被拆分为两页,并完成了页面方向的纠正。

二、手动设置区域功能
在图像识别的过程中,我们也有一些小技巧可以使用。
当我们将图像导入到OCR编辑器时,ABBYY FineReader PDF 15会自动进行图像区域的识别。
在一些特殊的情况下,如识别证件图像时,我们可能需要准确地保留原文的格式,在这种情况下,我们可以运用手动区域设置的功能,将识别为文本的区域,修改为图片区域,保留其原来的格式。
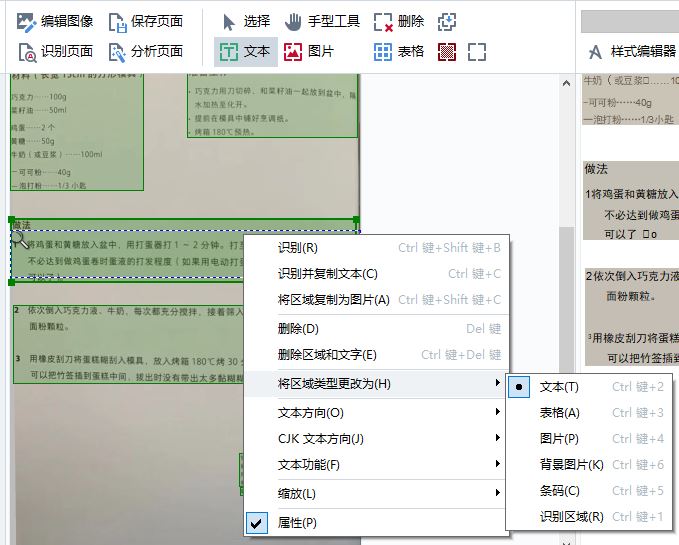
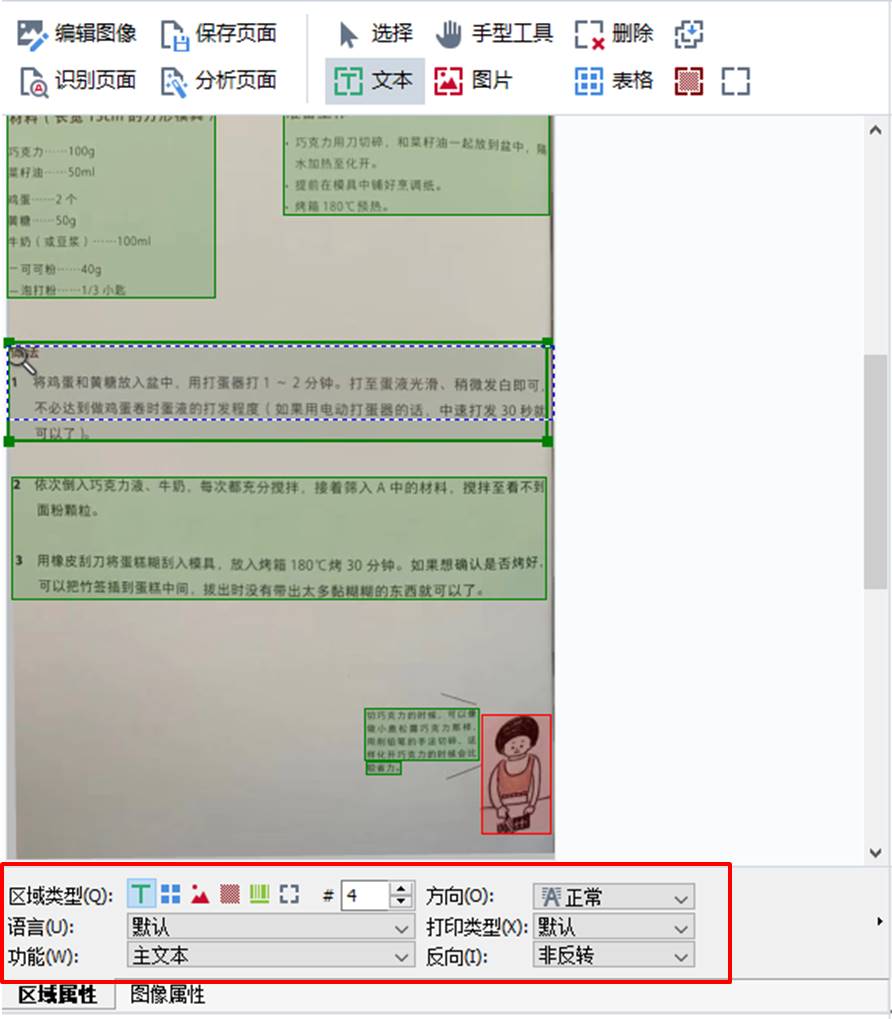
除了手动设置区域功能外,ABBYY FineReader PDF 15还提供了区域属性的功能,以帮助我们识别一些特殊的文本格式,如反转的文本、旋转过的文本等。
三、快速查找错误字符
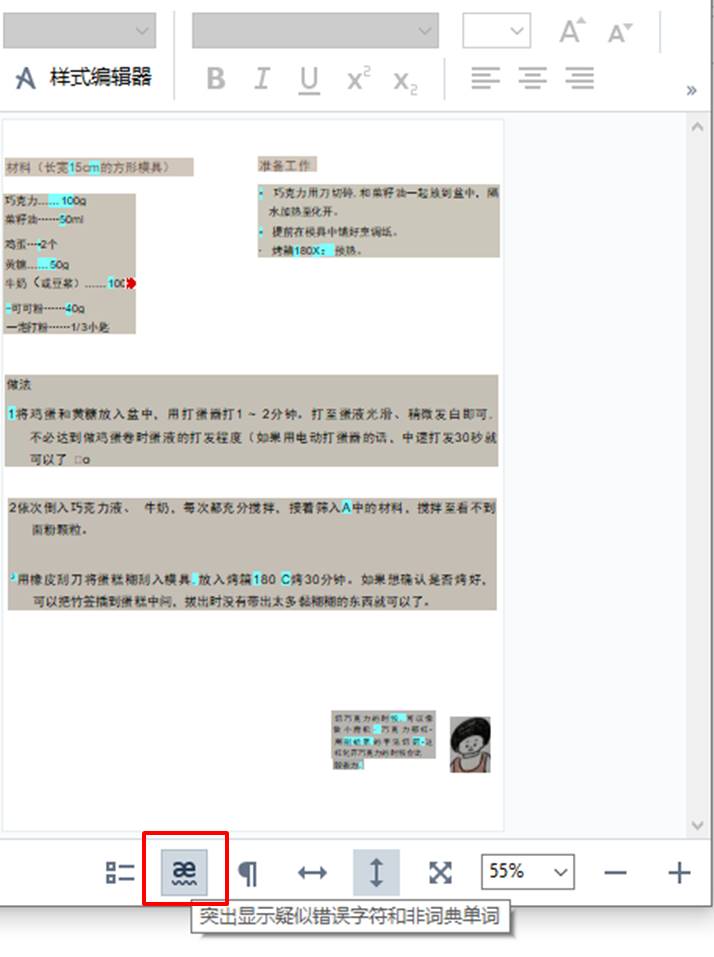
如果所需识别的图像包含大量文本时,我们如何才能快速地检查文本识别的准确度?实际上,ABBYY FineReader PDF 15已为我们提供了便捷的检查功能。
如图8所示,单击文本编辑面板底部的“突出显示疑似错误字符”按钮,即可标亮一些疑似错误的字符,实现快速检查的目的。
四、小结
综上所述,ABBYY FineReader PDF 15提供的OCR文本识别功能,不仅能帮助我们识别图像上的文本,而且还提供了多项便捷的功能辅助文本识别。
比如,通过使用图像预处理功能,可纠正一些拍摄失误;通过使用手动区域设置功能,可灵活地设置文本识别的区域等。
作者:泽洋
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:
PDF如何转换Word文档 PDF转word格式乱了怎么调整
对于一些经常需要处理文档的工作者来说,文档的格式转换是十分常见的。然而我们在将PDF文件转换成Word文档时会出现格式乱了的情况,那么我们接下来就来说一说PDF如何转换Word文档,PDF转Word格式乱了怎么调整。...
阅读全文 >

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >
pdf扫描的文件是歪的怎么办 pdf扫描件歪了如何调整
经常和文件扫描打交道的人都知道,如果文件没有摆正,扫描出来的pdf容易变歪。如果pdf扫描的文件是歪的怎么办呢?pdf扫描件歪了如何调整呢?以下会为大家提供解决方法。...
阅读全文 >
如何把JPG图片转换成Word文字 JPG图片转换成Word的软件有哪些
如今许多文字内容都是以图片格式展示出来的,因为图片看起来更美观更能够让人眼前一亮,但如果想要将图片中的内容转换为文字却并不简单,把文字一个一个的在键盘上敲起来,不仅浪费时间效率还低,那么应该怎么办呢?下面小编就来为大家讲讲如何把JPG图片转换成Word文字,JPG图片转换成Word的软件有哪些?...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 